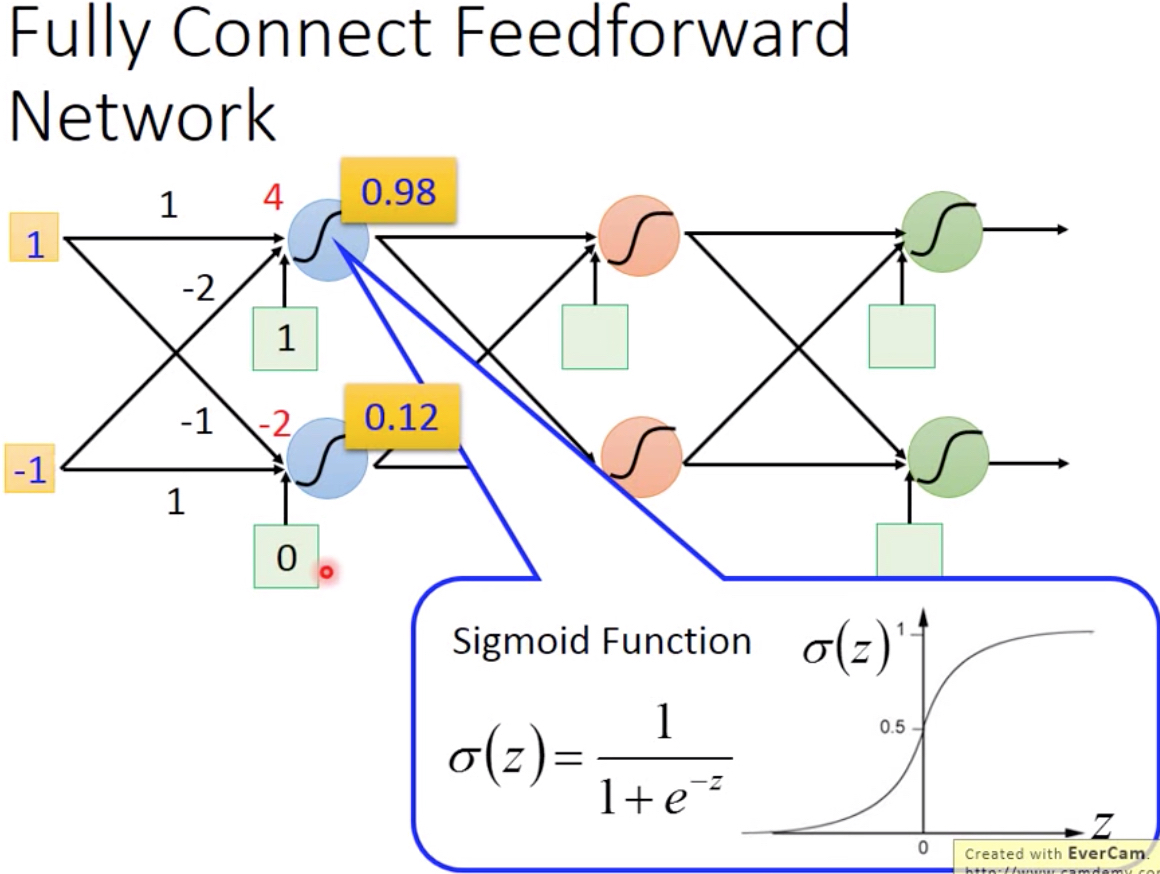
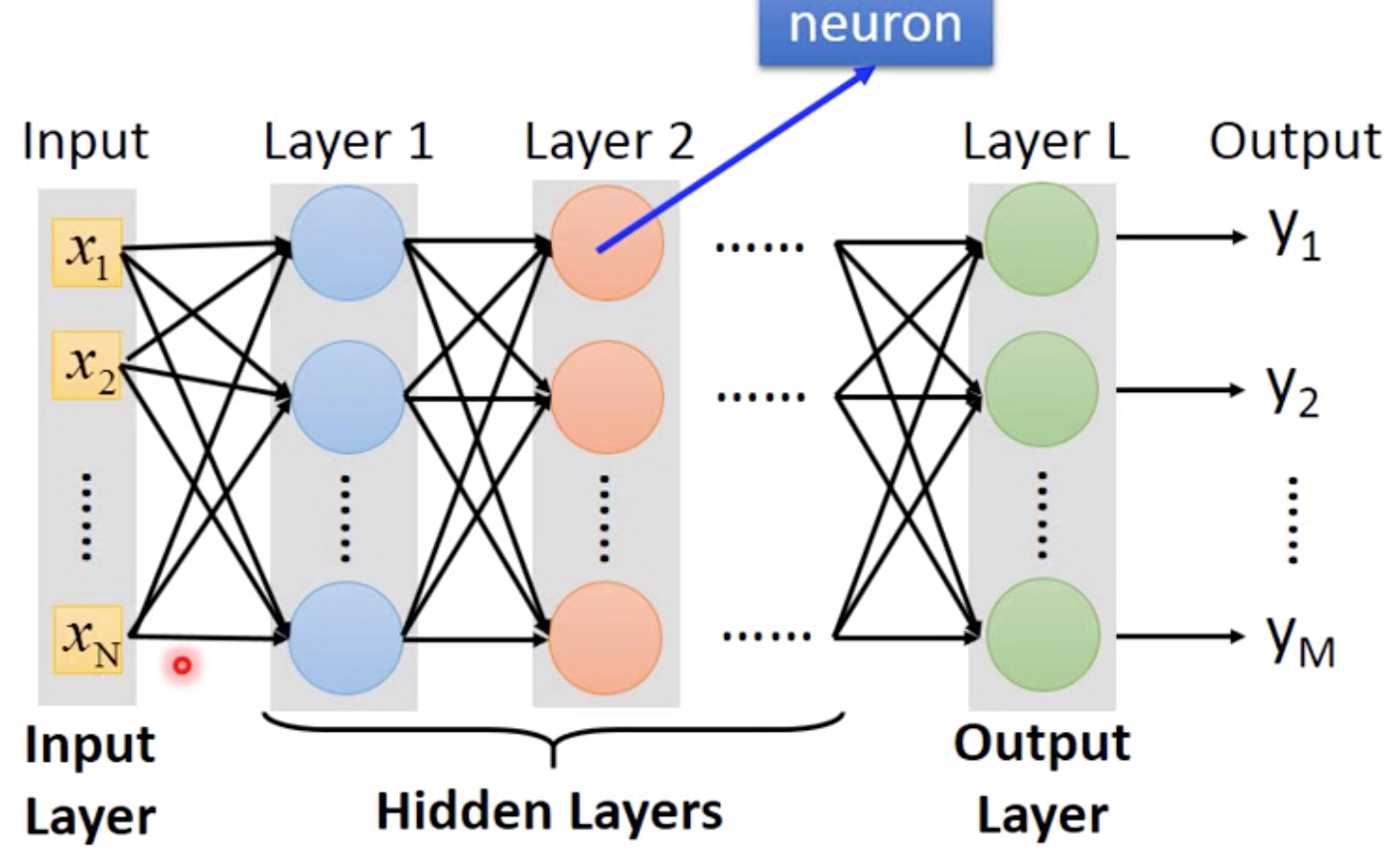
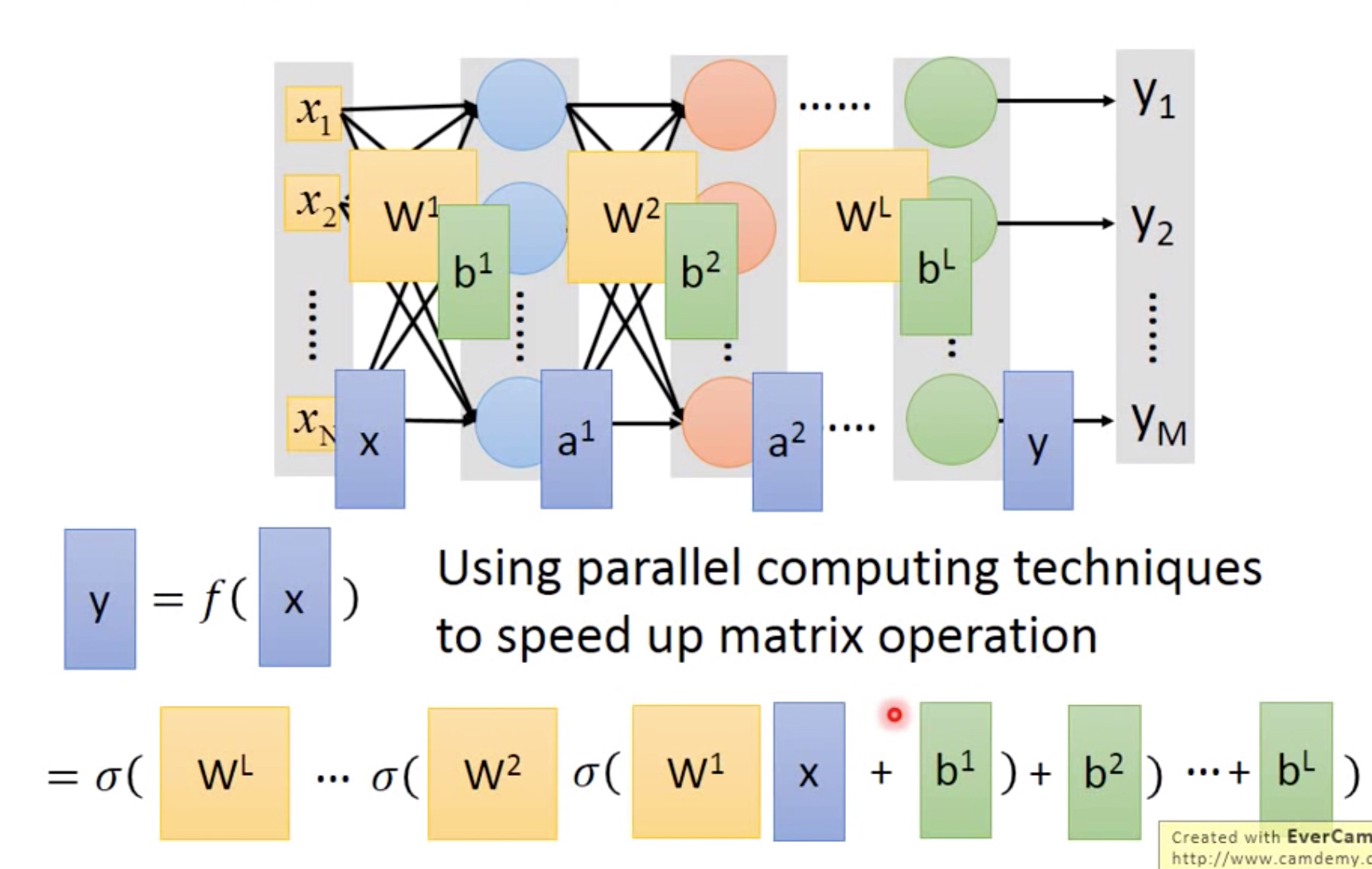
import numpy as np import os import matplotlib.pyplot as plt import keras from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation from keras.utils import np_utils from keras import backend as K
# 多核 CPU 使用设置 K.set_session(K.tf.Session(config=K.tf.ConfigProto(device_count={"CPU": 8}, inter_op_parallelism_threads=8, intra_op_parallelism_threads=8, log_device_placement=True)))
defforward(self, x): out = self.fc1(x) out = self.relu(out) out = self.fc2(out) return out
model = NeuralNet(input_size, hidden_size, num_classes).to(device)
# 4 Loss and optimizer 定义损失和优化函数 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
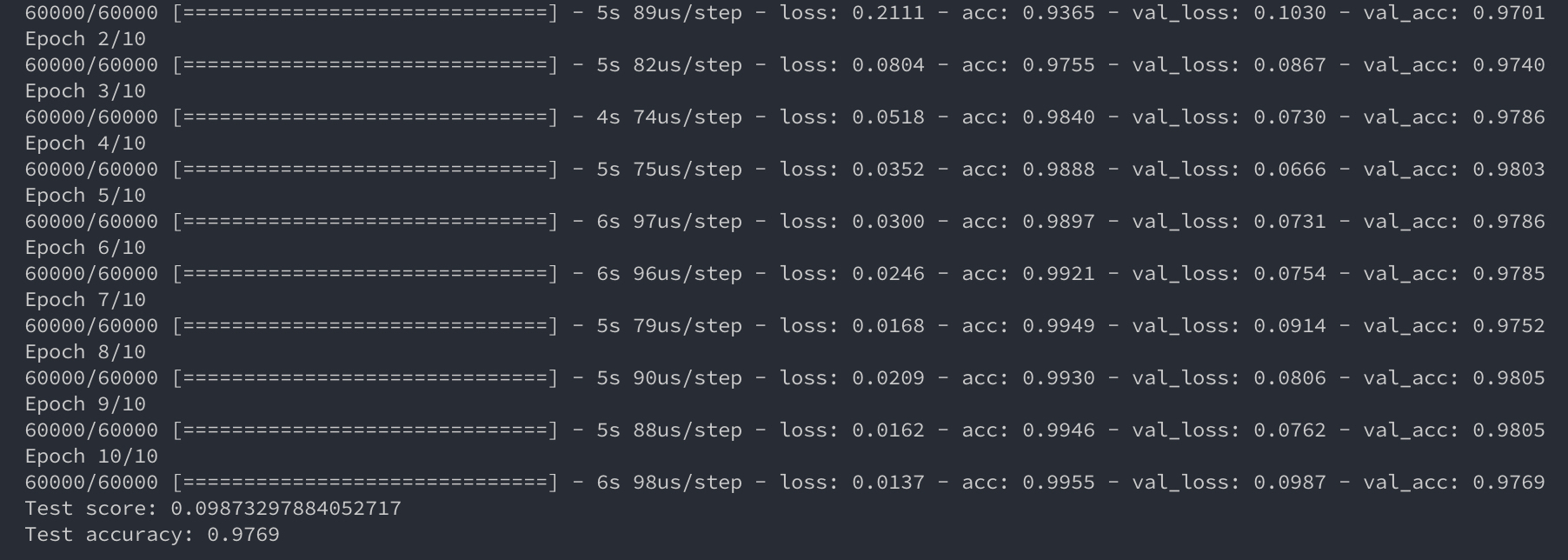
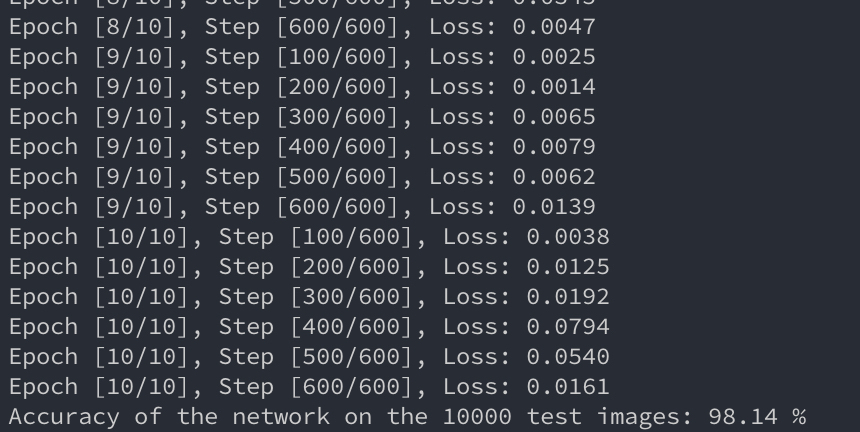
# 5 Train the model 训练模型 total_step = len(train_loader) for epoch inrange(num_epochs): for i, (images, labels) inenumerate(train_loader): # batch size的大小 # Move tensors to the configured device images = images.reshape(-1, 28*28).to(device) labels = labels.to(device)
# Test the model 预测 # In test phase, we don't need to compute gradients (for memory efficiency) with torch.no_grad(): correct = 0 total = 0 for images, labels in test_loader: images = images.reshape(-1, 28*28).to(device) labels = labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %' .format(100 * correct / total))
# Save the model checkpoint torch.save(model.state_dict(), 'model.ckpt')