Original Paper Reference:HiddenCut: Simple Data Augmentation for Natural Language Understanding with Better Generalizability - ACL Anthology
Source Code: GT-SALT/HiddenCut (github.com)
Introduction
Fine-tuning large-scale pre-trained language models (PLMs) has become a dominant paradigm in the natural language processing community, achieving state-of-the-art performances in a wide range of natural language processing tasks.
After task-specific fine-tuning, models are very likely to overfit and make predictions based on spurious patterns, making them less generalizable to out-of-domain distributions.
即是大模型微调已成为新的 NLP 范式,但存在特定任务泛化性不足的问题,即是有限的数据上过拟合,对于 OOD 数据又很差的表现。
现有的一些解决思路:
In order to improve the generalization abilities of over-parameterized models with limited amount of task-specific data, various regularization approaches have been proposed, such as adversarial training that injects label-preserving perturbations in the input space, generating augmented data via carefully-designed rules, and annotating counterfactual examples. Despite substantial improvements, these methods often require significant computational and memory overhead or human annotations.
现有的正则化方法如上,存在计算量和手工标注的代价。
本文的工作主要是利用 dropout 机制的思想,虽然在 plm 模型中已经存在此类机制,但面对 OOD 数据依然存在问题,作者认为其原因有二:
The underlying reasons are two-fold: (1) the linguistic relations among words in a sentence is ignored while dropping the hidden units randomly. In reality, these masked features could be easily inferred from surrounding unmasked hidden units with the self-attention networks. Therefore, redundant information still exists and gets passed to the upper layers. (2) The standard dropout assumes that every hidden unit is equally important with the random sampling procedure, failing to characterize the different roles these features play in distinct tasks.
一个是语言本身是互相蕴含的,随机掩盖一个词,可以很轻松的根据其上下文猜测出这个词,等于没有掩盖。二是随机掩盖忽略了隐藏单元本身的重要性不同的分布。
当前已有利用 Cutoff 方法来对输入空间token、feature、span 进行去除,因此这些信息在训练阶段将无法可见,但是当预测的关键线索被删除的时候,会造成严重的数据噪声干扰。
为了解决这些限制,作者提出了一种新方法——HiddenCut。
Specifically, the approach is based on the linguistic intuition that hidden representations of adjacent words are more likely to contain similar and redundant information.
HiddenCut drops hidden units more structurally by masking the whole hidden information of contiguous spans of tokens after every encoding layer. This would encourage models to fully utilize all the task-related information, instead of learning spurious patterns during training.
To make the dropping process more efficient, we dynamically and strategically select the informative spans to drop by introducing an attention based mechanism.
By performing HiddenCut in the hidden space, the impact of dropped information is only mitigated rather than completely removed, avoiding injecting too much noise to the input.
We further apply a Jensen-Shannon Divergence consistency regularization between the original and these augmented examples to model the consistent relations between them
具体解释如上,即是建立在相邻词语的隐藏表示会包含类似的冗余的信息。HiddenCut 通过更加结构化的掩盖每一个编码层的隐藏单元连续的 token 片段信息,实现模型对任务相关信息的充分利用而不是学习其中的虚假模式。
为了使 drop 过程更加有效,通过引入注意力机制来动态的有策略的选择drop 片段。而且通过在隐藏层执行信息掩盖,不会使 drop 的信息被完全删除,而是得到缓解,从而避免向输入注入过多的噪声信息。
并进一步在原始示例和这些增强示例之间应用Jensen-Shannon散度一致性正则化来模拟它们之间的一致性关系。
论证方法有效性的:
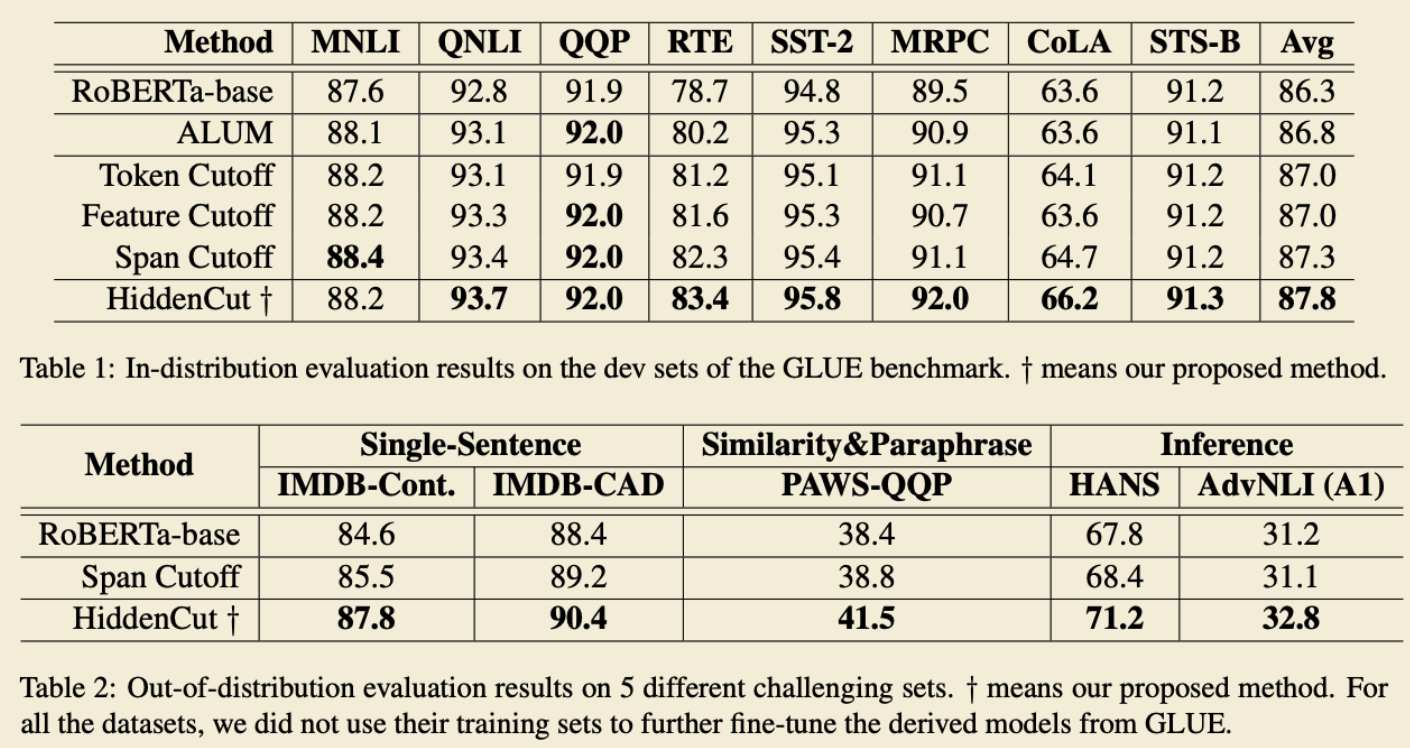
we conduct experiments to compare our HiddenCut with previous state-of-the-art data augmentation method on 8 natural language understanding tasks from the GLUE benchmark for in-distribution evaluations, and 5 challenging datasets that cover single-sentence tasks, similarity and paraphrase tasks and inference tasks for out-of-distribution evaluations.
We further perform ablation studies to investigate the impact of different selecting strategies on HiddenCut’s effectiveness.
Results show that our method consistently outperforms baselines, especially on out-of-distribution and challenging counterexamples.
方法
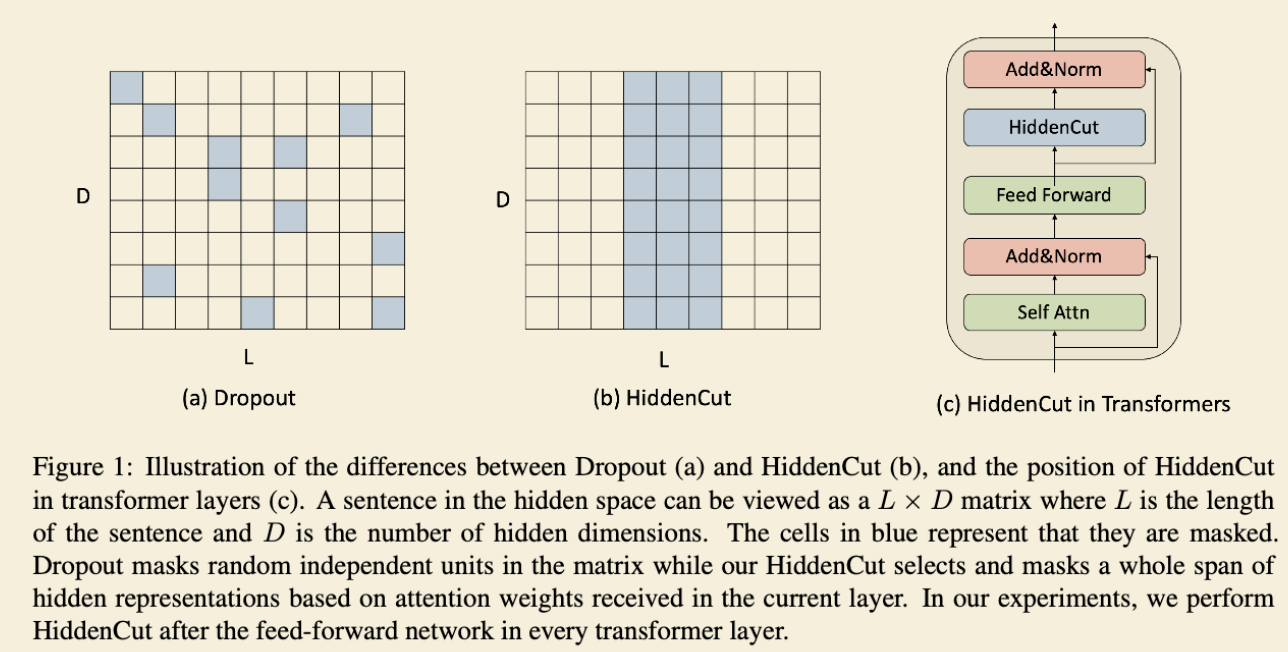
基于注意力的采样策略cut 的信息范围:
Intuitively, we can drop the spans of hidden representations that are assigned high attentions by the transformer layers. As a result, the information redundancy is alleviated and models would be encourage to attend to other important information.

损失目标函数
其中 $p_{avg}$ stands for the average predictions across the original text and all the augmented examples.
将此三者结合,便是总的目标函数:
实验
总体实验结果,GLUE 和 OOD 实验。
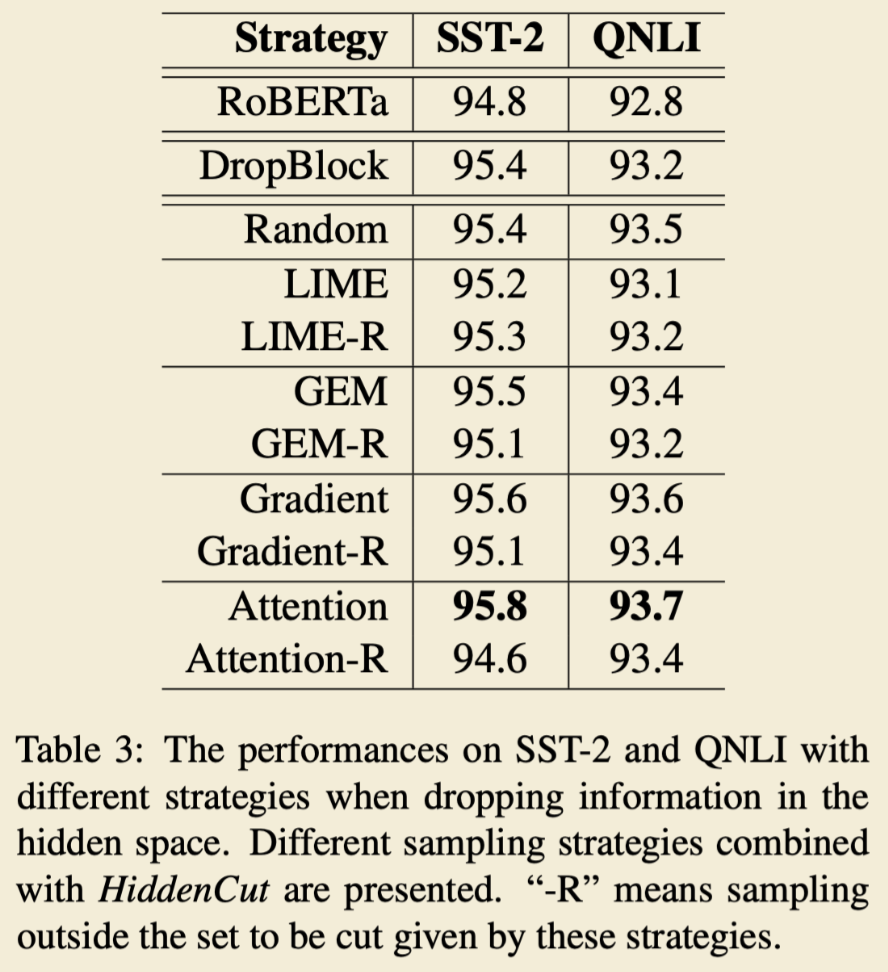
hidden units 采样策略实验:
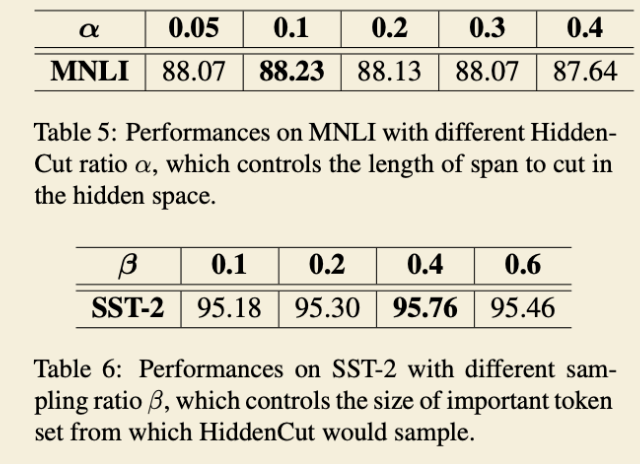
超参数选择实验:
结论
In this work, we introduced a simple yet effective data augmentation technique, HiddenCut, to improve model robustness on a wide range of natural language understanding tasks by dropping contiguous spans of hidden representations in the hidden space directed by strategic attention based sampling strategies. Through HiddenCut, transformer models are encouraged to make use of all the task-related information during training rather than only relying on certain spurious clues.
Through extensive experiments on in-distribution datasets (GLUE benchmarks) and out-of-distribution datasets (challenging counterexamples), HiddenCut consistently and significantly outperformed state-of-the-art baselines, and demonstrated superior generalization performances.
方法看起很简单,效果看起来也很不错。这种在隐藏层实现模型泛化和数据增强的方法真是棒,无需制造更多的原始数据。
除了这种基于注意力的方法,能否更加具有针对性的针对词与任务相关性,词语与标签相关性的角度来进行增强呢?

