Introduction
文章提出了一个解决 实体-关系抽取 问题的新范式。
文章要解决的问题如下:
We need to extract four different types of entities,i.e., Person, Company, Time and Position, and three types of relations, FOUND, FOUNDING-TIME and SERVING-ROLE.
比如下面这段文本:

转换后的结果为下面的结构化形式:
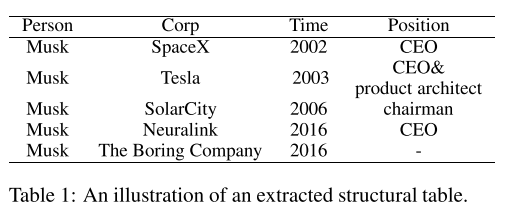
文章将上述结构化文本形式化为:REL(e1,e2)REL(e1,e2),其中e1e1和e2e2是实体,RELREL是关系。
解决这一问题的当前的方法模型主要有两种:流水线模型和联合模型。

但是当前这些模型都存在一些问题:
三元组的形式化问题。类似于三元组REL(e1,e2)REL(e1,e2)这样的形式不能充分表现文本背后的结构化信息,因为往往在文本中存在层级性的依赖关系。比如上面的文本,Time 的抽取要依赖 Position,而 Position 的抽取要依赖 Company。独立地考虑两种实体可能导致依赖关系的间断。
算法程序上本身的问题,现存的模型都是输入一个文本句子和两个标记实体,输出是这两个实体间是否有关系,对于这样的神经模型而言,识别上述形式化中的词汇、语义和句法线索是非常困难的,特别是当:
实体相距很远;
一个实体出现在多个三元组中;
一个句子包含多个同类关系,关系跨度相交
所以,在本文中,我们把 ERE 视为一种多轮问答任务:每种实体类型和每种关系类型都用一个问答模板进行刻画,从而这些实体和关系可以通过回答这些模板化的问题来进行抽取。问题的答案就是文本的一段(span),所以我们就可以用阅读理解(MRC)的框架去解决。
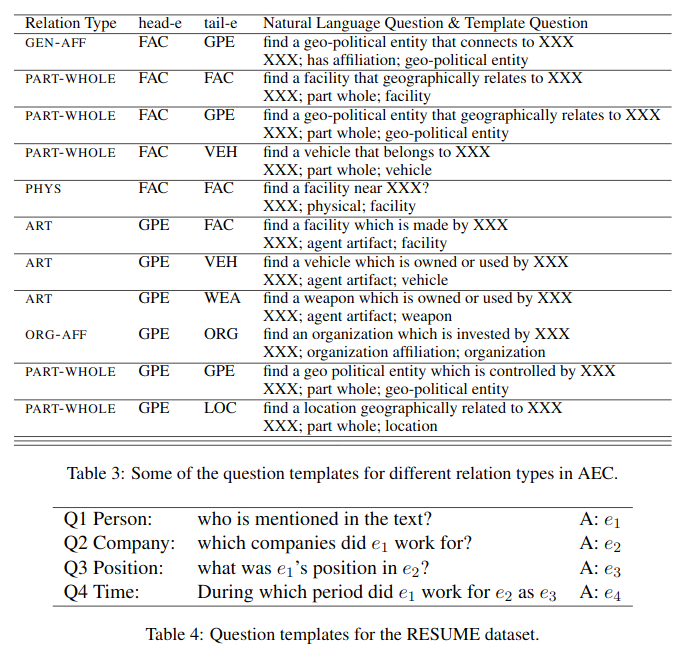
比如对于上面那段文字,为了抽取出类似上述表格的结构化形式结果,模型需要依次回答下面的问题:

利用这种方法处理问题的优点:
- 能够很好地捕捉层级化的依赖关系。
- 问题能够编码重要的先验关系信息,从而解决现存模型存的问题:远程实体对,关系相交等
- 问答框架是一种很自然的方法来同时提取实体和关系。
使用 QA 的方法在 ACE 和 CoNLL04 数据集上取得了非常好的效果,这些数据集上的任务被形式化为三元组抽取问题,所以经过两轮问答便足够了。同时文章作者也构建了一个 RESUME 数据集验证,需要四轮至五轮问答提取信息。
数据集
ACE04, ACE05 and CoNLL04
数据集定义的关系和实体类型如下:

对ACE04/05,我们按照(Li and Ji, 2014)和(Miwa and Bansal, 2016)中的划分方法,对CoNLL04,我们按照(Miwa and Sasaki, 2014)的划分方法。数据集的介绍详见论文。
模型
算法

整个抽取设计分为两步:
头实体抽取阶段(line 4 -9)
- 对所有类型的实体使用实体问题模板生成问题,在回答中抽取文本中的头实体集合
关系和尾实体抽取阶段(line10-24)
- 使用关系链模板和头实体生成问题,在回答中抽取尾实体和关系
强化学习

Conclusion
【待续】

